
ComfyUI | Generate video, images, 3D, audio with AI

요즘 여러 AI 서비스들이 많이 나오고 있습니다
다들 한번 쯤 들어보거나 사용해 본 chatGPT 부터 퍼플렉시티, 구글 제미나이
코딩 특화 AI인 커서 AI 나 깃허브 코파일럿 등등 그외에도 각 분야에 특화 된 AI들이 쏟아진다고 해도 과언이 아니죠
그 중에서 이미지, 동영상 관련 AI를 보면
이미지 생성 AI 중에 유명한 미드저니나
영상 생성 AI 구글의 veo시리즈나 오픈AI의 소라 등등 유명하죠
사실 금전적인 부분을 신경 안쓰신다면 그냥 상용서비스 돈내고 쓰는게 편합니다
고사양 하드웨어가 필요 없기도 하고 웹에서 생성하고 건당 요금만 지불하면 되니까요
하지만 금전적인 부분을 신경 안쓰기가 쉽지 않죠
가격 적인 부분 말고도 각 기업의 규정에 따른 제약도 있고요
이미지 생성 부분에 FLUX 라던가 오픈 소스 부분에 wan2.1 이나 Hunyauan 같은 모델이
이미지나 동영상을 생성할 수 있는 모델인데 오픈 소스로 풀려있습니다
초창기에는 AI를 로컬로 돌리기 위해 아주 높은 사양의 하드웨어가 필요했습니다만
요즘에는 경량화 된 모델임에도 괜찮은 결과를 뽑아주는 모델이 많이 생겼죠
어느 정도 성능이 되는 데스크탑을 가지고 계신다면 나름 쓸만합니다
물론 하드웨어 성능이 좋아질 수록 속도가 빨라지기 때문에 같은 시간에 더 많은 결과물을 얻을 수 있겠죠
ComfyUI Blog | Robin | Substack
comfyUI 블로그에 보시면 이런저런 새로 추가되는 모델들의 정보를 확인 할 수 있습니다
이미지 관련 로컬 AI 중에 유명한 게 스테이블 디퓨전이라는 게 있죠
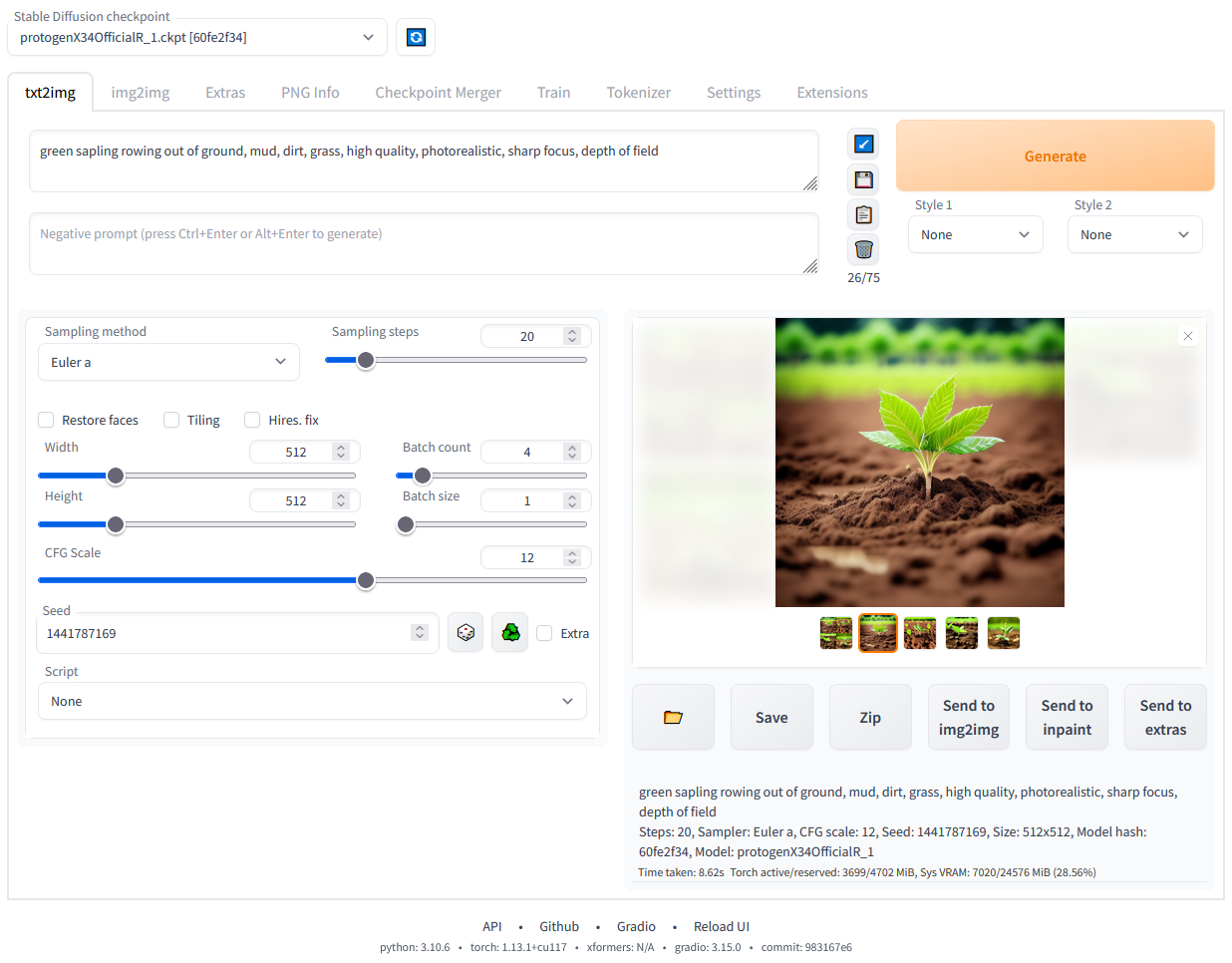
AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
온라인 서비스도 있습니다만 로컬 AI 툴인 Stable Diffusion webUI도 있습니다
이 웹UI 툴을 이용해서도 충분히 좋은 이미지를 뽑아 낼 수가 있습니다
사용법이 비교적 간단한 편이고 지원되는 모델들을 통해 정해진 태그나 프롬프트를 이용해 이미지를 생성 할 수 있죠
Civitai: The Home of Open-Source Generative AI
이미지 모델들은 주로 허깅페이스나 civitai 에서 다운을 받습니다
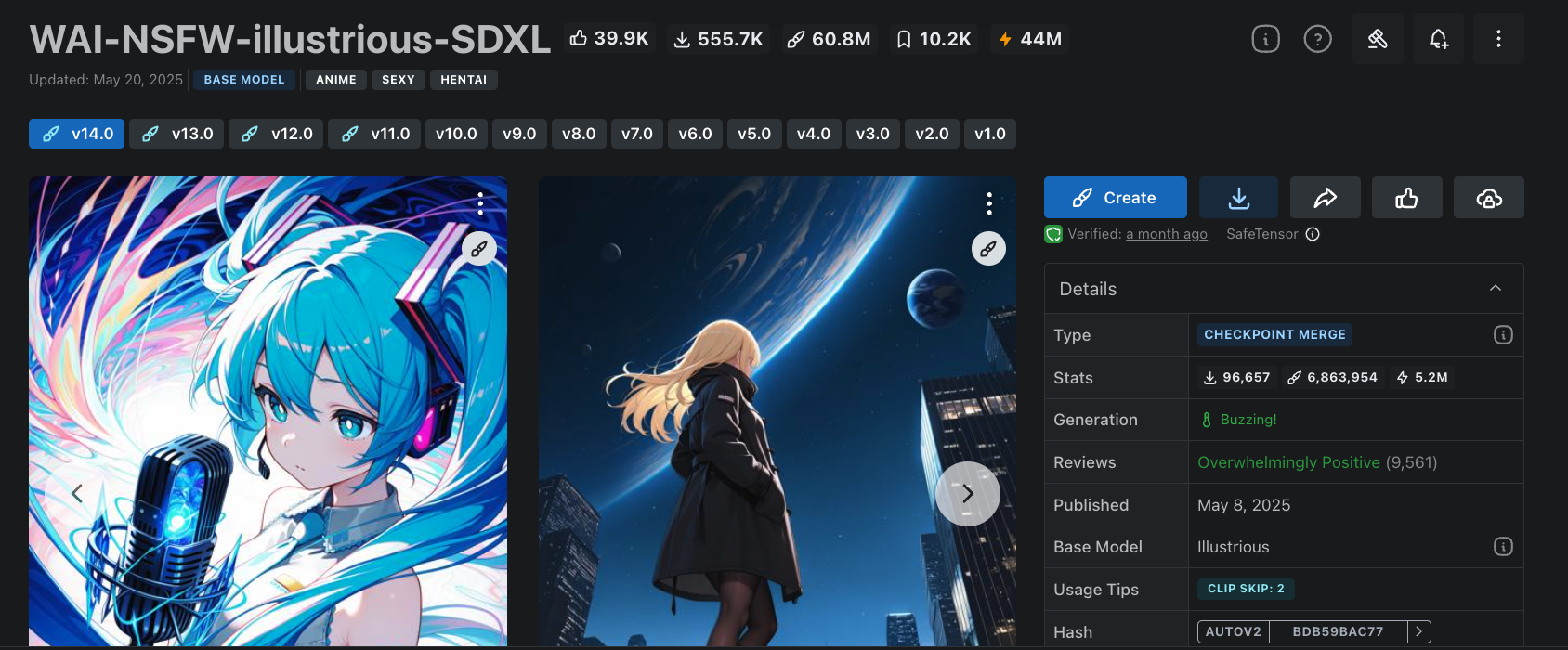
모델을 선택하면 우측에 타입은 체크포인트 혹은 로라라고 표시가 돼있는데
체크 포인트는 메인 모델로 쓸 수 있고
로라는 다른 메인 모델과 함께 써야하고 영향을 줄 수 있는 모델이다라고 생각하시면 됩니다
한 때 유행했던 지브리 모델로 보면 지브리 체크 포인트 모델은 모든 이미지를 지브리 모델로 생성 합니다만
지브리 로라 같은 경우는 다른 모델의 결과물을 지브리 스타일로 변형하는 형식 입니다
당연히 비율을 설정 할 수 있기 때문에 여러 개의 로라를 적절히 섞어서 원하는 스타일을 만들 수도 있습니다
여러 개의 로라를 특정 비율로 섞어서 저장도 가능 합니다
베이스모델은 어떤 모델을 기반으로 학습을 시켰느냐이고
제목에 SDXL 은 스테이블 디퓨전 XL 모델이라는 의미죠
SD 1.5나 SD 2.1 모델이 따로 있고 각각 생성 할 수 있는 이미지의 크기나 성능이 다릅니다
참고로 모델에 붙은 NSFW는 Not Safe For Work의 약자로 국내 커뮤니티에서 주로 사용하는 후방주의 같은 의미 입니다
성인등급? 이미지가 학습이 됐느냐 안됐느냐를 표시하는 거죠
어쨌든 이런 모델들을 기반으로 웹UI 만 가지고도 이미지 생성을 할 수는 있습니다만
세부적인 커스텀을 통해 결과물을 뽑아내고 싶은 경우 한계가 존재합니다
comfyUI 블로그를 둘러보시면 아시겠지만
SD 뿐만 아니라 여러가지의 모델들을 사용 할 수 있습니다
1. Stable Diffusion 계열
-
Stable Diffusion 1.5, 2.0, 2.1, SDXL, SDXL Turbo
-
DreamShaper, Juggernaut 등
-
안정화된 커스텀 체크포인트로, 다양한 스타일(실사, 만화, 예술 등) 지원1.
-
2. Video Generation (비디오 생성) 모델
-
Wan 2.1
-
HunyuanVideo
-
Mochi 1
-
Genmo AI의 오픈소스 비디오 생성 모델.
-
480p 해상도, 빠른 생성 속도, 프롬프트 정확도가 높음3.
-
다양한 프리시전(bf16, fp8) 지원.
-
3. 확장 및 특화 모델
-
FLUX 계열
-
HiDream
-
최신 텍스트-이미지 모델로, 다양한 버전(full, dev, fast) 지원.
-
ComfyUI 워크플로우에서 사용 가능.
-
-
Frame Pack
-
비디오 생성 및 프레임 기반 워크플로우에 특화된 모델.
-
커스텀 노드(예: Kijai, HM-RunningHub, TTPlanetPig 등)로 구현5.
-
-
PixArt
-
PixArt Sigma(512, 1024, 2K 해상도), PixArt LCM 등 다양한 체크포인트 지원.
-
SDXL VAE와 호환 필요6.
-
-
HunYuan DiT
-
Tencent의 DiT 기반 이미지 생성 모델.
-
ComfyUI_ExtraModels 확장에서 지원6.
-
-
MiaoBi
-
중국어 기반 이미지 생성 모델.
-
ComfyUI_ExtraModels 확장에서 지원6.
-
-
VAE, T5 등
-
다양한 VAE(변분 오토인코더) 및 T5 텍스트 인코더 지원6.
-
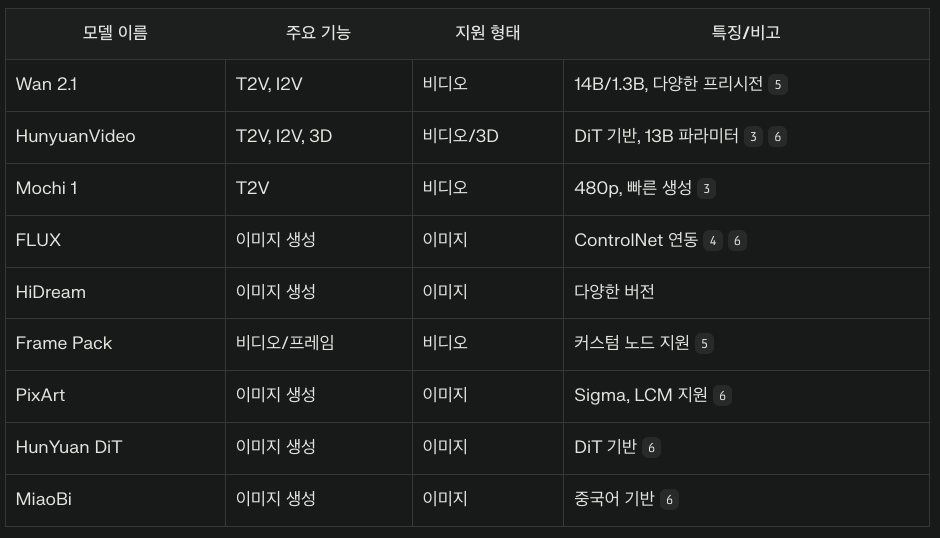
뭔가 많죠
프롬프트로 이미지를 생성하는 T2I 부터 이미지를 소스로 해서 이미지를 생성하는 I2I
프롬프트로 비디오를 생성하는 T2V, 이미지에서 비디오를 생성하는 I2V 까지 여러가지가 있습니다
물론 이렇게만 보면 comfyUI가 무조건 좋습니다만
단점이라고 해야할까요
설정이 복잡하고 각각의 커스텀 노드들이 오류를 일으키는 경우가 많습니다
이게 python 버전이라던가 각각의 플러그인 버전과 하드웨어 호환성에 따라 작동이 되기도 하고 안되기도 합니다
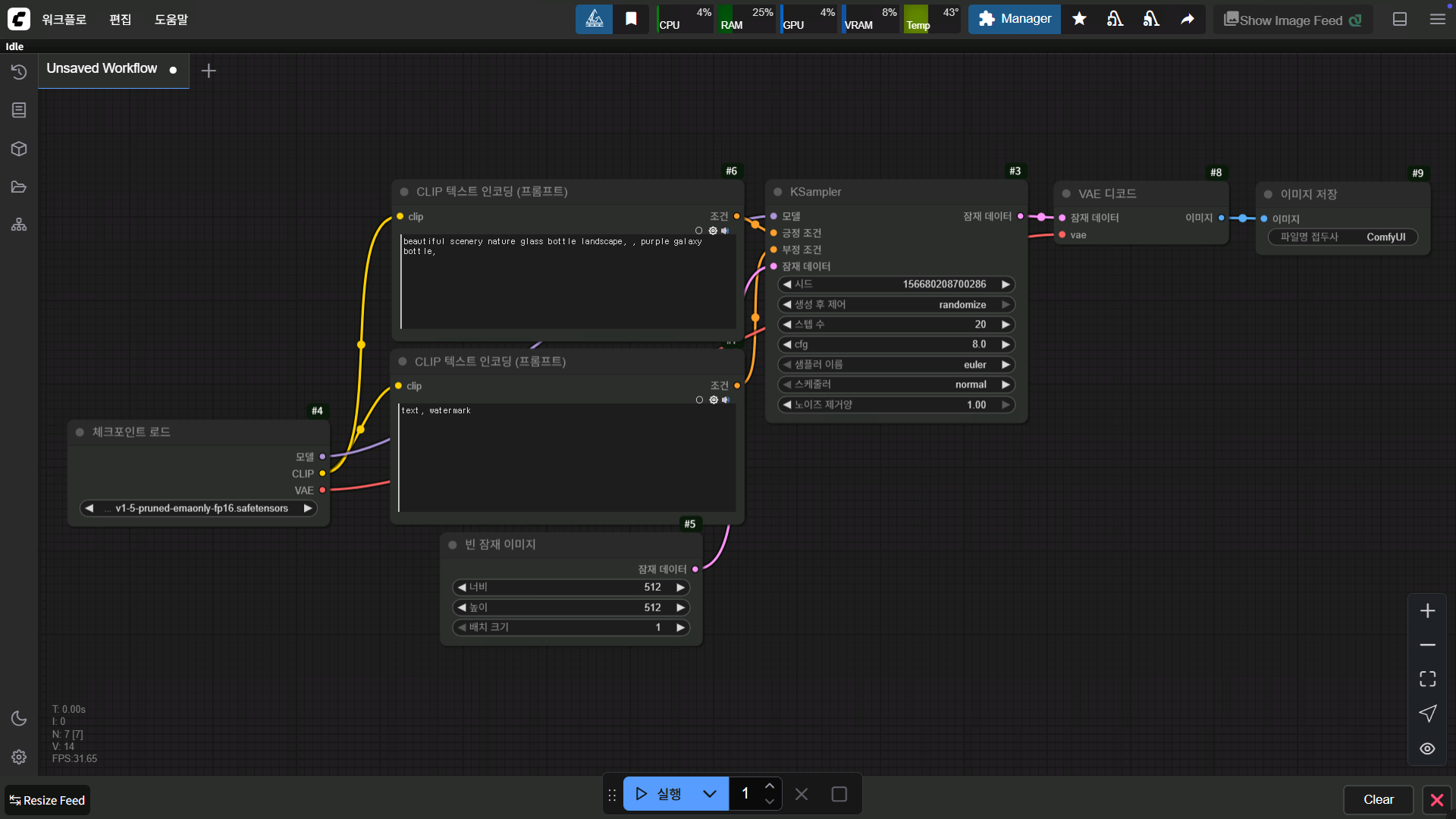
comfyUI는 이런 식으로 구성 돼있습니다
워크플로우에 노드를 구성해서 원하는 작업을 하는 거죠
저 워크플로우가 기본 워크플로우 인데 노드를 하나하나 보시면 간단 합니다
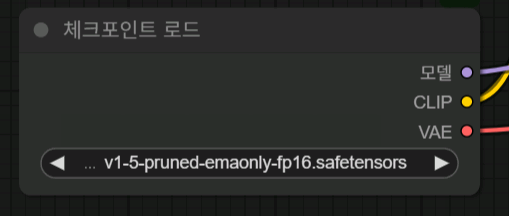
처음에 체크포인트 로드 노드에서 위에서 이야기 했던 체크포인트 모델을 로드 합니다
보시면 모델, CLIP, VAE 이렇게 세 가지 정보가 출력 됩니다
세가지 모델을 하나로 만든 체크포인트 모델인 경우 위 처럼 사용해도 상관 없습니다만
좀 더 성능 좋은 혹은 내가 원하는 결과물을 뽑을 수 있는 각각의 모델을 사용해도 됩니다
메인 모델, CLIP 모델, VAE 모델 이렇게 세 가지 모델을 사용 하는 거죠
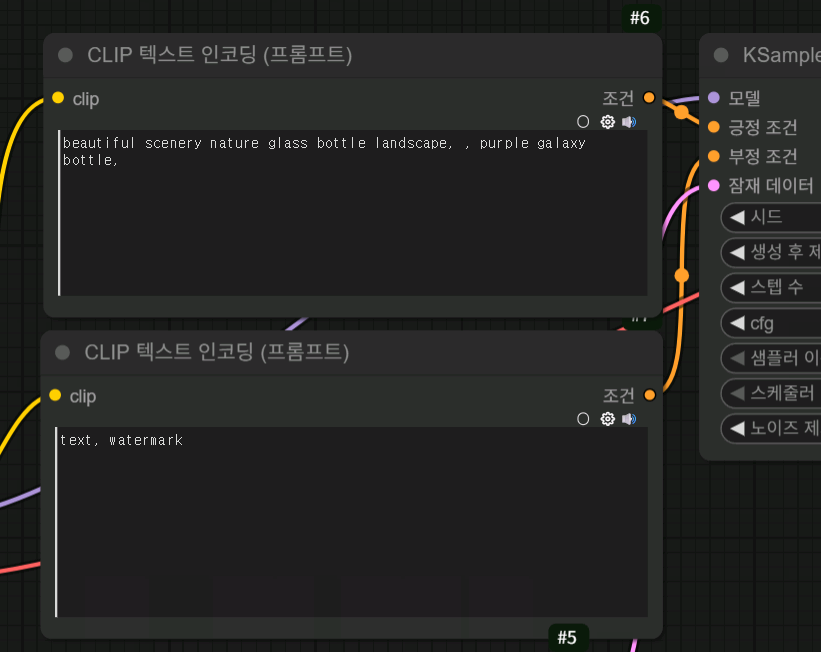
그 후에 CLIP 텍스트 노드에서 위에 건 긍정 프롬프트로 사용하고 아래 노드는 부정 프롬프트로 사용하는 거죠
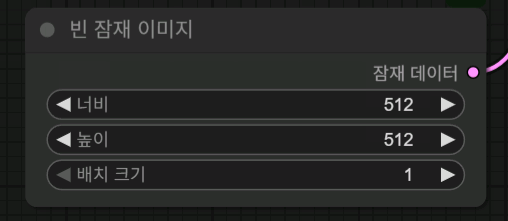
빈 잠재 이미지는 캔버스 크기라고 생각하시면 됩니다
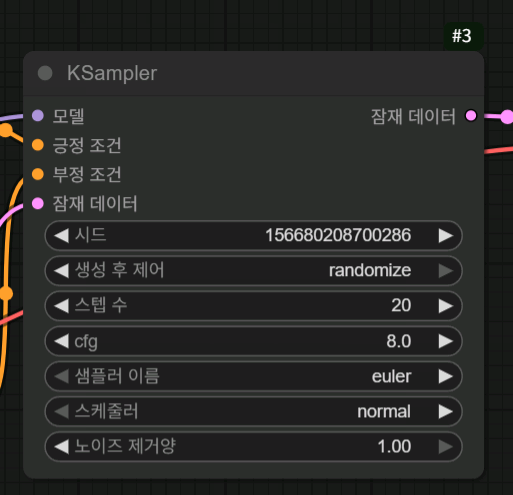
ksampler에서 설정에 따라 이미지를 생성하죠
여기서 이미지 기본 생성 원리를 간단하게 설명을 하자면
우선 이미지 생성을 시작하면 빈 잠재 이미지 크기에 맞게 노이즈가 가득 찬 잠재 이미지를 생성 합니다
그리고 스텝 수에 따라 노이즈 패턴을 예측하고 단계별로 노이즈를 제거해서 이미지를 완성하는 구조 입니다
CFG 값은 그 방향을 프롬프트에 얼마나 가깝게 적용하느냐 정도로 이해하시면 될 거 같습니다
더 복잡하고 어려운 알고리즘이나 원리가 있겠지만 궁금하신 분들은 관련 논문을 참고하시면 되겠습니다
어쨌든 원리를 대충 아셨으니 스텝 수가 높으면 더 고품질의 이미지가 만들어지겠다 라고 생각하실 수 있겠죠
물론 스텝 수가 늘어날 수록 시간도 늘어납니다
그렇다고 무조건 높게 설정한다고 좋은 건 또 아니고요
대략 2~30 스텝 정도 설정하고 사용을 합니다 그 이상 늘어나도 효율이 좋지 않고요
저 같은 경우 모델에 따라 다르지만 주로 20스텝 정도 사용해서 뽑아보고 내리거나 올리거나 해보는 편입니다
샘플러나 스케쥴러에 따라 생성되는 이미지가 다릅니다
이 부분도 조절을 해서 사용해야 하죠
civitai 의 모델들은 적정 옵션들을 표시해두기도 합니다
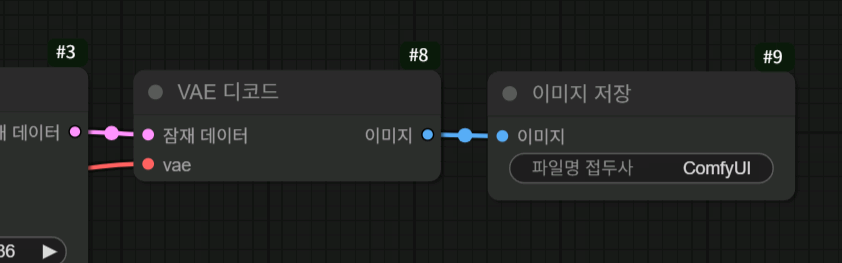
ksampler에서 이미지가 생성 완료 되면 잠재 데이터로 출력이 됩니다
이 잠재 데이터를 우리가 볼 수 있는 이미지로 바꾸기 위해서 VAE 디코드 노드를 통해 변환하고
저장을 합니다
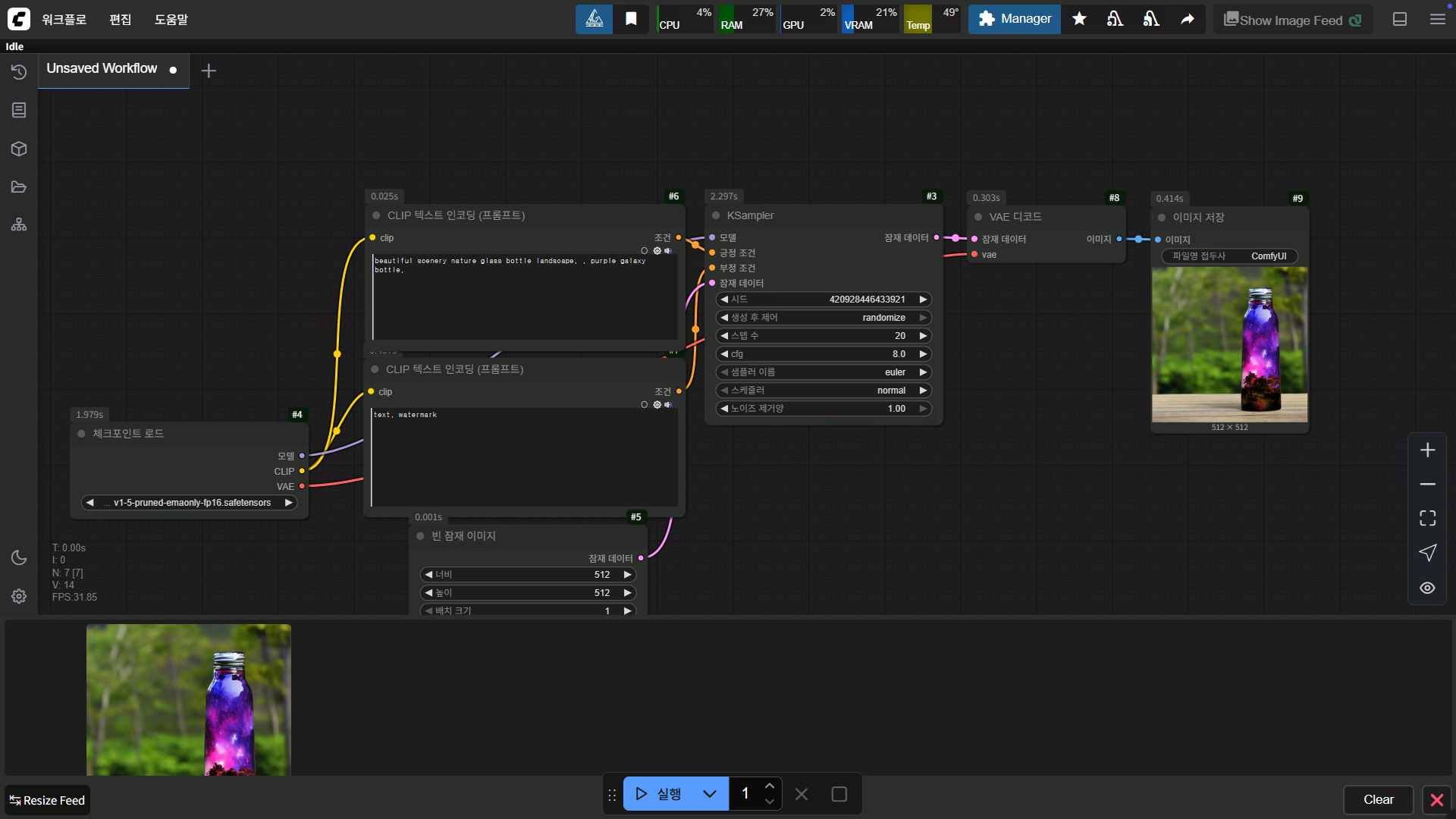

긍정 프롬프트의 내용에 따라 이런 이미지가 만들어지는 거죠

생성 되는데 5초 정도 걸렸네요
하지만 이 워크플로우는 말 그대로 기본 워크 플로우고요
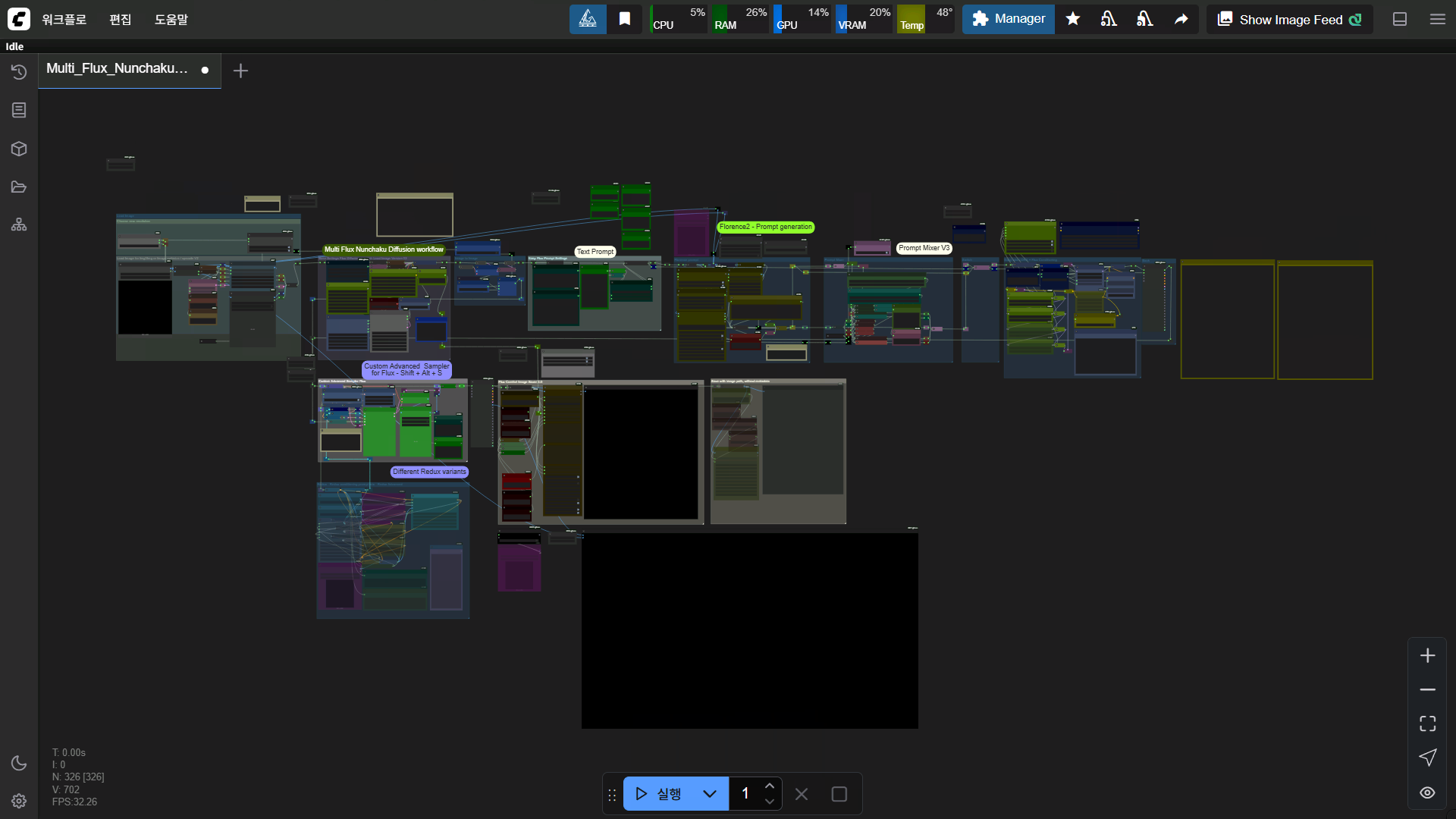
이런저런 기능들을 추가하다 보면 이 정도로 복잡해질 수도 있습니다
물론 제가 직접 만든 워크 플로우는 아니고요
라는 이름의 워크플로우를 가져다가 수정해서 사용 하는 거죠
워크플로우에 여러 기능과 단계를 추가해서
인페인팅이나 아웃페인팅을 통해 캐릭터의 의상을 교체하거나 제품 사진을 교체하거나
얼굴이나 머리 색 같은 외형 뿐만 아니라 배경과 사진 안의 텍스트등등 전부 수정 가능합니다
단순히 이미지가 아니라 영상으로도 가능하고요

유튜브에 여러 가이드 영상들이 있지만
이 분의 영상들이 퀄리티가 좋더라고요
진짜 상업적으로 사용해도 손색이 없겠다 싶은 수준의 가이드를 올려주십니다
워크플로우도 전부 공개를 해주시고요
원하는 기능이 있으시면 이 분 영상 목록에서 한 번 찾아보시면 좋을 거 같습니다
글이 길어졌는데 다음 글은 아마도 comfyUI 설치 글이나
flux, hidream, nunchaku, framepack, wan2.1 같은 모델 관련 글이 될 거 같네요
최근에는 노래를 만들 수 있는 ace-step 이라는 모델도 나왔습니다
아 그리고 설치 해보실 분들은
포터블 버전, comfyUI 데스크탑 앱 버전, 스테이빌리티 매트릭스 버전이 있는데
스테이빌리티 매트릭스 버전으로 설치하시길 바랍니다
제가 5070ti로 처음에 포터블 버전 중에 5070ti 지원 되는 베타 버전으로 설치 했다가
새로 나오는 모델들이 설치가 안되서 꼼수를 통해 데스크탑 앱 버전으로 설치해서 썼었는데
결국 또 새로운 모델 설치가 안되더라고요
파이썬, 파이토치 버전이 너무 최신이라서 안맞거나 해당 버전에 맞는 플러그인 버전이 없어서 설치가 안되거나
이런 식이라 문제가 좀 있었는데 스테이빌리티 매트릭스에서는 별다른 설정 없이 설치 잘 됐습니다
다른 유저들이 많이 사용하는 구?버전이라 다른 내용들도 적용 잘 되고요
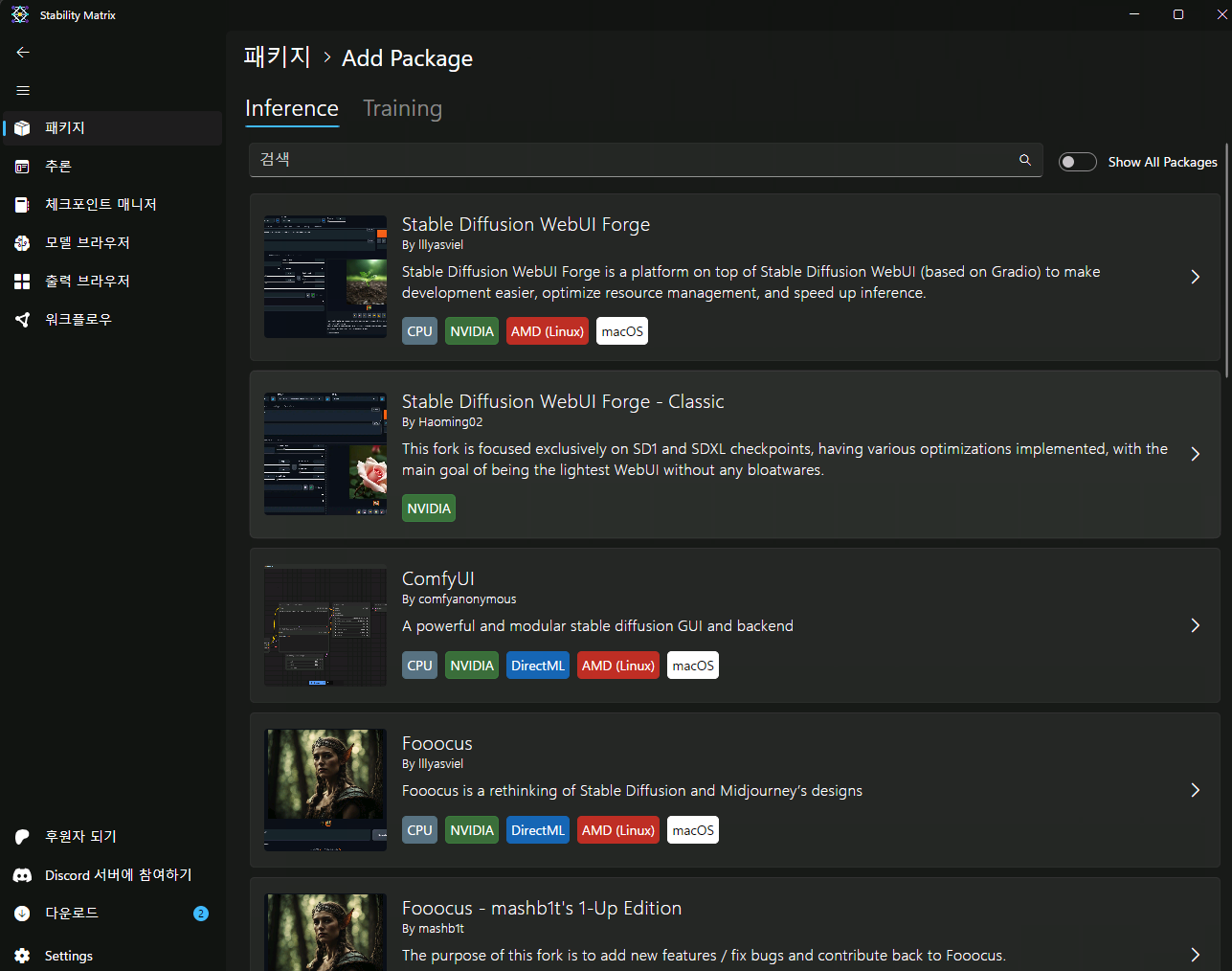
스테이빌리티 매트릭스에는 comftUI 말고 다른 이미지 생성 로컬 AI들도 설치 가능하고
다운로드 한 모델을 각각의 로컬AI에서 공유가 가능해서 관리나 사용이 편하기도 합니다